
How to Make Data Requests
Web scraping, also known as data extraction, is the process of retrieving, thus scraping,
data from a website. Developers use certain HTTP methods to manipulate data, usually using APIs.
Below we’re going to go over how to get data from my social tracker blog, mb4.in.
A cheat-sheet containing ES2015 [ES6] tips, tricks, best practices and code snippet examples for your day to day workflow.
Intro
Our first example can be done from the command line. Fire up your terminal, and try a cURL:
curl -X GET \
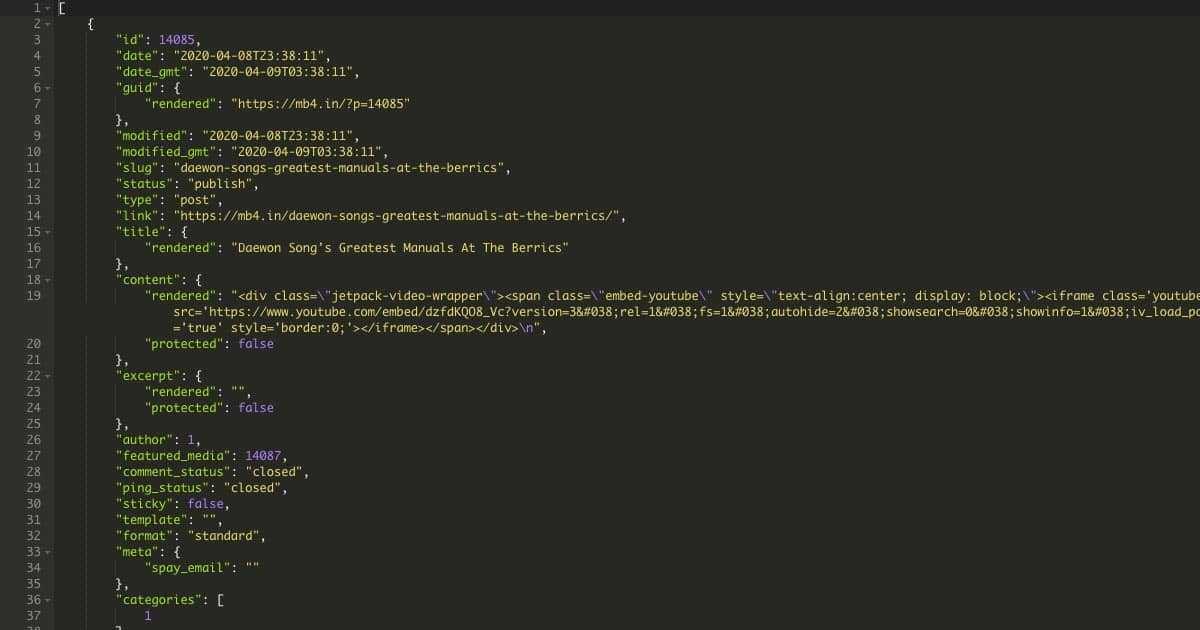
'https://mb4.in/?rest_route=/wp/v2/posts&per_page=1'Your results should something similar to:
[
{
"id": 14085,
"date": "2020-04-08T23:38:11",
"date_gmt": "2020-04-09T03:38:11",
"guid": {
"rendered": "https://mb4.in/?p=14085"
},
"modified": "2020-04-08T23:38:11",
"modified_gmt": "2020-04-09T03:38:11",
"slug": "daewon-songs-greatest-manuals-at-the-berrics",
"status": "publish",
"type": "post",
"link": "https://mb4.in/daewon-songs-greatest-manuals-at-the-berrics/",
"title": {
"rendered": "Daewon Song’s Greatest Manuals At The Berrics"
},
"content": {
"rendered": "<div class=\"jetpack-video-wrapper\"><span class=\"embed-youtube\" style=\"text-align:center; display: block;\"><iframe class='youtube-player' type='text/html' width='640' height='360' src='https://www.youtube.com/embed/dzfdKQO8_Vc?version=3&rel=1&fs=1&autohide=2&showsearch=0&showinfo=1&iv_load_policy=1&wmode=transparent' allowfullscreen='true' style='border:0;'></iframe></span></div>\n",
"protected": false
},
"excerpt": {
"rendered": "",
"protected": false
},
"author": 1,
"featured_media": 14087,
"comment_status": "closed",
"ping_status": "closed",
"sticky": false,
"template": "",
"format": "standard",
"meta": {
"spay_email": ""
},
"categories": [
1
],
"tags": [
46
],
"jetpack_featured_media_url": "https://mb4.in/wp-content/uploads/2020/04/dzfdKQO8_Vc.jpg",
"_links": {
"self": [
{
"href": "https://mb4.in/wp-json/wp/v2/posts/14085"
}
],
"collection": [
{
"href": "https://mb4.in/wp-json/wp/v2/posts"
}
],
"about": [
{
"href": "https://mb4.in/wp-json/wp/v2/types/post"
}
],
"author": [
{
"embeddable": true,
"href": "https://mb4.in/wp-json/wp/v2/users/1"
}
],
"replies": [
{
"embeddable": true,
"href": "https://mb4.in/wp-json/wp/v2/comments?post=14085"
}
],
"version-history": [
{
"count": 1,
"href": "https://mb4.in/wp-json/wp/v2/posts/14085/revisions"
}
],
"predecessor-version": [
{
"id": 14086,
"href": "https://mb4.in/wp-json/wp/v2/posts/14085/revisions/14086"
}
],
"wp:featuredmedia": [
{
"embeddable": true,
"href": "https://mb4.in/wp-json/wp/v2/media/14087"
}
],
"wp:attachment": [
{
"href": "https://mb4.in/wp-json/wp/v2/media?parent=14085"
}
],
"wp:term": [
{
"taxonomy": "category",
"embeddable": true,
"href": "https://mb4.in/wp-json/wp/v2/categories?post=14085"
},
{
"taxonomy": "post_tag",
"embeddable": true,
"href": "https://mb4.in/wp-json/wp/v2/tags?post=14085"
}
],
"curies": [
{
"name": "wp",
"href": "https://api.w.org/{rel}",
"templated": true
}
]
}
}
]This is the standard response from a Wordpress website. It contains the entire post, the title, content, url, taxonomies and references to other data.
I personally like to use wget when making command line requests, here’s how that’d
look (more human readable):
wget --quiet \
--method GET \
--header 'Cache-Control: no-cache' \
--output-document \
- 'https://mb4.in/?rest_route=/wp/v2/posts&per_page=1'PHP
We’ll start with PHP. There’s a few different ways to GET data from a remote URL, in this instance,
https://mb4.in/?rest_route=/wp/v2/posts&per_page=1. This will return the latest post from my blog.
First, lets see how its done with PHP cURL:
<?php
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => "https://mb4.in/?rest_route=/wp/v2/posts&per_page=1",
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => "",
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 30,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => "GET",
CURLOPT_HTTPHEADER => array(
"Cache-Control: no-cache"
),
));
$response = curl_exec($curl);
$err = curl_error($curl);
curl_close($curl);
if ($err) {
echo "cURL Error #:" . $err;
} else {
echo $response;
}If you place this into a php document and run a local server, say: php -S localhost:9000,
then hit that URL, in your browser you should the response:
Next example uses the pecl_http library:
<?php
$client = new http\Client;
$request = new http\Client\Request;
$request->setRequestUrl('https://mb4.in/');
$request->setRequestMethod('GET');
$request->setQuery(new http\QueryString(array(
'rest_route' => '/wp/v2/posts',
'per_page' => '1'
)));
$request->setHeaders(array(
'Cache-Control' => 'no-cache'
));
$client->enqueue($request)->send();
$response = $client->getResponse();
echo $response->getBody();and lastly, HTTPRequest:
<?php
$request = new HttpRequest();
$request->setUrl('https://mb4.in/');
$request->setMethod(HTTP_METH_GET);
$request->setQueryData(array(
'rest_route' => '/wp/v2/posts',
'per_page' => '1'
));
$request->setHeaders(array(
'Cache-Control' => 'no-cache'
));
try {
$response = $request->send();
echo $response->getBody();
} catch (HttpException $ex) {
echo $ex;
}Python
I love how simple and clean code is in Python. Here’s how to make a request using
the default http.client library in Python 3:
import http.client
conn = http.client.HTTPConnection("mb4,in")
headers = {
'Cache-Control': "no-cache"
}
conn.request("GET", "", headers=headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))and if you want things even simpler, give Requests a spin:
import requests
url = "https://mb4.in/"
querystring = {"rest_route":"/wp/v2/posts","per_page":"1"}
headers = {
'Cache-Control': "no-cache"
}
response = requests.request("GET", url, headers=headers, params=querystring)
print(response.text)Javascript
For Javascript, not including Node, there’s two major methods. These examples will output their
results in the console. First is AJAX using jQuery:
var settings = {
"async": true,
"crossDomain": true,
"url": "https://mb4.in/?rest_route=/wp/v2/posts&per_page=1",
"method": "GET",
"headers": {
"Cache-Control": "no-cache"
}
}
$.ajax(settings).done(function (response) {
console.log(response);
});This second example works intependent of jQuery:
var data = null;
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
xhr.addEventListener("readystatechange", function () {
if (this.readyState === 4) {
console.log(this.responseText);
}
});
xhr.open("GET", "https://mb4.in/?rest_route=/wp/v2/posts&per_page=1");
xhr.setRequestHeader("Cache-Control", "no-cache");
xhr.send(data);Node
Node isn’t too far off from how its done in Javascript, for obvious reasons. Let’s start with the native Node method first:
var http = require("https");
var options = {
"method": "GET",
"hostname": [
"mb4",
"in"
],
"path": [
""
],
"headers": {
"Cache-Control": "no-cache"
}
};
var req = http.request(options, function (res) {
var chunks = [];
res.on("data", function (chunk) {
chunks.push(chunk);
});
res.on("end", function () {
var body = Buffer.concat(chunks);
console.log(body.toString());
});
});
req.end();It’s far cleaner and simpler to just use the request library:
var request = require("request");
var options = { method: 'GET',
url: 'https://mb4.in/',
qs: { rest_route: '/wp/v2/posts', per_page: '1' },
headers:
{ 'Cache-Control': 'no-cache' } };
request(options, function (error, response, body) {
if (error) throw new Error(error);
console.log(body);
});Ruby
Lastly is Ruby:
require 'uri'
require 'net/http'
url = URI("https://mb4.in/?rest_route=/wp/v2/posts&per_page=1")
http = Net::HTTP.new(url.host, url.port)
request = Net::HTTP::Get.new(url)
request["Cache-Control"] = 'no-cache'
response = http.request(request)
puts response.read_bodyObjective C
I’m not aan iOS developer, but I thought I’d also include this, mostly to compare to how wild it looks compared to other languages.
#import <Foundation/Foundation.h>
NSDictionary *headers = @{ @"Cache-Control": @"no-cache" };
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:[NSURL URLWithString:@"https://mb4.in/?rest_route=/wp/v2/posts&per_page=1"]
cachePolicy:NSURLRequestUseProtocolCachePolicy
timeoutInterval:10.0];
[request setHTTPMethod:@"GET"];
[request setAllHTTPHeaderFields:headers];
NSURLSession *session = [NSURLSession sharedSession];
NSURLSessionDataTask *dataTask = [session dataTaskWithRequest:request
completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
if (error) {
NSLog(@"%@", error);
} else {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *) response;
NSLog(@"%@", httpResponse);
}
}];
[dataTask resume];